I still love the Command and Query Responsibility Segregation (CQRS) and Event Sourcing (ES) architectural patterns, so when the popular Java based Axon Framework went GA with release 3.0 recently, I figured now would be a great time to revisit this topic and update the code from my previous CQRS & Event Sourcing microservices demo.
Source code
The code for this new demo can be found here on GitHub and includes a README with instructions on how to build it and run it for yourself on Pivotal Web Services or PCF-Dev. If you want to compare and contrast with the code for the old demo, it can also be found here on GitHub.
Podcast
There is now an accompanying ‘Pivotal Insights’ podcast available on soundcloud.
Axon Events
We’ll be demonstrating Axon on Pivotal CloudFoundry in a live demo at the AxonIQ conference in Amsterdam on the 29th September 2017 – just one part of a fun-packed day-long CQRS/ES feast-ival. Book your tickets here…
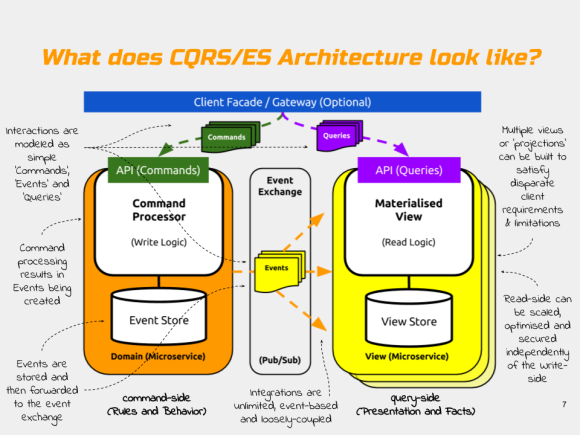
Architectural Overview.
I’m not going to provide any code samples in this article (if you want to you can explore the code for yourself in this GitHub repository). I’m also going to skip any in depth explanations of how CQRS and Event Sourcing work (just take a look at the resources section below if that’s something that you’re interested in exploring further). However, I would like to give you a brief overview of the CQRS architecture used in this particular project.
As you can see in the diagram below, just like last time, this new CQRS project models a simple set of ‘Product Catalog’ API’s. And again, just like last time, the application is physically segregated into two parts: the command-side and the query-side microservices.
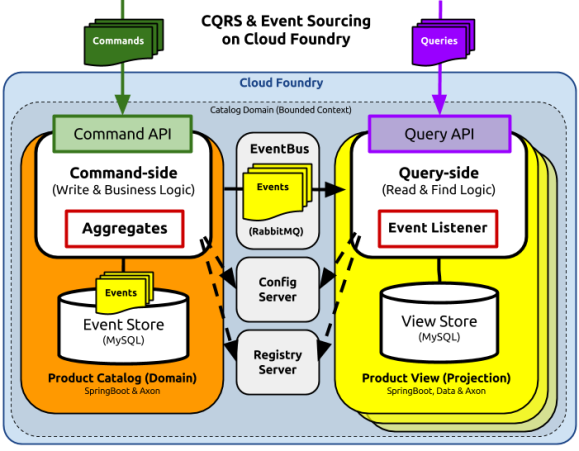
Clients of these microservices can add Products to the catalog using a command (a simple JSON structure) that is POSTed to the command-side REST API (/add). Clients can also query for the products currently in the catalog using a GET request on the query-side REST API (/products).
The command-side and the query-side components live in separate processes; only communicate using events; and never directly with each other. They use a publish/subscribe messaging service to communicate in order to maintain a loose coupling between them.
The commands in the system such as AddProductToCatalog trigger behaviours. The events (such as ProductAdded) are the result of executing those behaviours. The events form the basis of all communication between the microservices and also support the event-sourcing persistence mechanism. The persistence mechanism (called the Event Store) offers the means to reconstruct or ‘source’ the state of an individual Product in the catalog at any time.
It’s worth noting that in this simple demo, there is no mechanism through which you can reliably ‘replay’ the events into the query-side model. To replay events with Axon, you need to attach a Tracking Event Processor to the Event Store. This gives you fine grained control over which messages to replay.
Because we’re using a CQRS, it’s expected that you would ultimately have lots of different query-side apps (such as views, projections, reports and legacy adapters etc.). Each query-side application would be a tightly focussed and self-contained microservice. This helps you to maintain the flexibility of your architecture and prevents your microservices reverting into monoliths as new feature requests come along.
If the API fragmentation that results as a side effect of this pattern is a concern for you, you could always use an API gateway to give the appearance of weaving these separate API’s back together – as a BFF for example.
So What’s New in the Demo Code?
In this new demo, you’ll spot a few of major differences in the project’s code, configuration, and build. From a high level, both the microservice code and it’s deployment into the cloud have been greatly simplified in this new incarnation.
Axon V3 has much better support for Spring Boot.
Previously, integrating Axon with Spring Boot was a bit of a pain. I remember had to dig fairly deeply into the configuration of the framework in order to get it all wired together in a way that was sensible and transparent.
Thankfully, with this new V3 release, Axon now offers first class support for Spring Boot. Axon has become far easier to configure, and has several helpful starter JAR’s and annotations that make the process much simpler.
The CommandGateway, for example, is automatically configured for you with default settings and is added to the Application Context as a Spring Bean at startup. All you have to do to benefit from this is include the axon-spring-boot-starter as a dependency in your build.
Bye Bye Docker!
Another major improvement in this new version is a wholesale move away from Docker towards the Cloud Foundry platform. If you’re new to Cloud Foundry or you haven’t heard of Cloud Foundry before, it’s basically a open-source cloud container orchestrator which provides a rich application platform for cloud-native applications. Cloud Foundry is designed with developers in mind and offers an easy to use CLI interface that abstracts away a great deal of the complexity associated with managing containers in the cloud.
Cloud Foundry offers everything I need to run microservice applications at scale, but without any of the associated operational overheads. Out of the box, CloudFoundry offers self-service provisioning of both application containers and backing services, self-healing, auto-scaling, distributed logging and monitoring and a great many other things. These features improve my development productivity immensely and it means I have far fewer components to configure and manage in production.
Compared to my 2015 demo, now I’m using Cloud Foundry, there’s a lot of ‘stuff‘ that I no longer have to do for myself. For example, in the earlier demo, in order to package up the application to run it in the cloud, I had to create and maintain several Docker images (6 in total for this one logical microservice application group).
But now, because Cloud Foundry comes with a marketplace of application backing services (provisioned using the Open Service Broker API standard that Kubernetes will use), I can instantly provision services like databases and messaging servers using the cf create-service command in the terminal. That’s four Docker images that I no longer have to worry about securing, patching, configuring, building and pushing.
Similarly, Cloud Foundry Buildpacks are a way of automatically bundling up my code into open RunC containers and scheduling them. This means that I can simply “push” my application’s JAR file using the cf push command and Cloud Foundry will take my code and run it in the cloud for me. It’s a really simple mechanism, and it allows me to retire two more of my six Docker images. This deployment workflow can be easily scripted and also makes zero-downtime blue-green deployment strategies a total cinch to implement.
Hello Concourse.
Finally, this time around I’ve also included a sample continuous integration pipeline that can be used to build, unit-test, deploy, smoke-test and integration-test the Product Catalog API. I’m using use the open source Concourse server as the CI server for this.

I really like Concourse. It treats ‘pipelines’ as a first class citizen (unlike Jenkins); it’s cloud friendly (unlike Jenkins), it allows you to keep your build configuration with your code (unlike Jenkins), and it integrates nicely with Cloud Foundry.
Wrapping Up.
Axon has come a long way with this release. It’s fair to say there are still some aspects that aren’t quite as intuitive or polished as perhaps they could be (I’m looking at you “Event Processing Groups” and you “documentation“), but the improved integration with SpringBoot is much appreciated. The amount of boilerplate code required to configure Axon has diminished considerably, and it’s still a great framework with which to implement a truly Domain-Driven Design.
As for the move to Cloud Foundry, obviously, I realise that Docker looks great from a CV perspective, but when you have to maintain the security and OS patch levels of hundreds of Docker images in production (and also orchestrate them so that applications can self-heal and auto-scale) the novelty of using Docker images for code packaging soon wears off. Besides, I genuinely like the developer workflow in Cloud Foundry, and when you see how much effort goes into basics like OS hardening on the Cloud Foundry platform, you’re bound to wonder why anyone would contemplate doing this themselves.
I hope you find this project a useful introduction to Java based CQRS on Cloud Foundry, and a viable template for getting you started quickly with Axon v3 and Spring Boot. Feel free to use the comments feature or contact me on social media if you would like to get in touch or ask me questions about it.
Additional Resources: I was inspired to revisit this demo by watching “Bootiful CQRS with Axon” by Josh Long of Pivotal and Allard Buijze of Trifork. The book “The CQRS Journey” from Microsoft is a great resource and the eBook version is completely free to download and read. Domain Driven Design Distilled by Vaughn Vernon isn’t free, but it is very readable and it covers a much broader set of topics and describes CQRS and Event Sourcing in a much wider DDD context. This CQRS article by Martin Fowler is also very popular. Finally, this presentation by Greg Young talks about Event Sourcing on the JVM and mentions Axon.
About the Author
Ben Wilcock works for Pivotal as a Senior Solutions Architect. Ben has a passion for microservices, cloud and mobile applications and helps Pivotal’s Cloud Foundry customers to become more responsive, innovate faster and gain greater returns from their software investments. Ben is a respected technology blogger who’s articles have featured in DZone, Java Code Geeks, InfoQ, Spring Blog and more.





You must be logged in to post a comment.